
Azure Automated ML offers a quick and easy way to train baseline models for all sorts of machine learning tasks such as regression, classification, and time series forecasting. In this article I’ll show you how to reverse engineer an Azure AutoML model, decompose it into its atomic components, and use those components to create your own model, all without any Azure ML SDK dependencies.
This is, by the way, the second article in my series on building an end-to-end machine learning system. If you have the time, I recommend you also go through the previous article in this series, to gain a bit more context.
But why train your own model instead of relying on automated machine learning? For starters, AutoML is good at training one-off models but most models need regular retraining to maintain their performance. For example, I’ve previously used AutoML to train a time series forecasting model, and used that model to predict tomorrow’s closing price for Ethereum. Training a one-off automated ML model worked acceptably well, however its forecasts got worse and worse the farther we went into the future1. A one-off model is definitely not a good solution in this case.
In order to get good results we need a regularly updated model, and in order to regularly update our model we need to run Automated ML every time the data is updated. Depending on how often we want to retrain your model, running AutoML for each and every data update may be a bit prohibitive, both cost and performance-wise.
It makes more sense to just run AutoML to train a baseline model, analyze and duplicate the functionalities of said baseline, and use the results to create your own model that’s cheaper and faster to retrain. And that’s just what we’ll do.
Picking the Right Model
Before doing any sort of analysis, we need to decide which of the 50+ trained models we want to look at. Usually this means the best-performing model, but in this case I’ll skip that one and go straight for the second-best.
You see, once Azure AutoML thinks it has tested enough regular models, it likes to gather the 5-7 best-performers into a voting ensemble. By combining the forecasts of different models an ensemble balances out their individual weaknesses and will usually display better performance than any of the individual models.
However, trying to duplicate all of those individual models might be a bit overkill for what we’re trying to achieve, and this is why I’ll skip the best model – an ensemble – and go straight for the second, regular one. However, you should know that the lessons learned in this article do apply to the individual models in the ensemble too, and there’s nothing stopping you from rewriting and joining them using something like scikit-learn’s VotingRegressor to create a corresponding model.
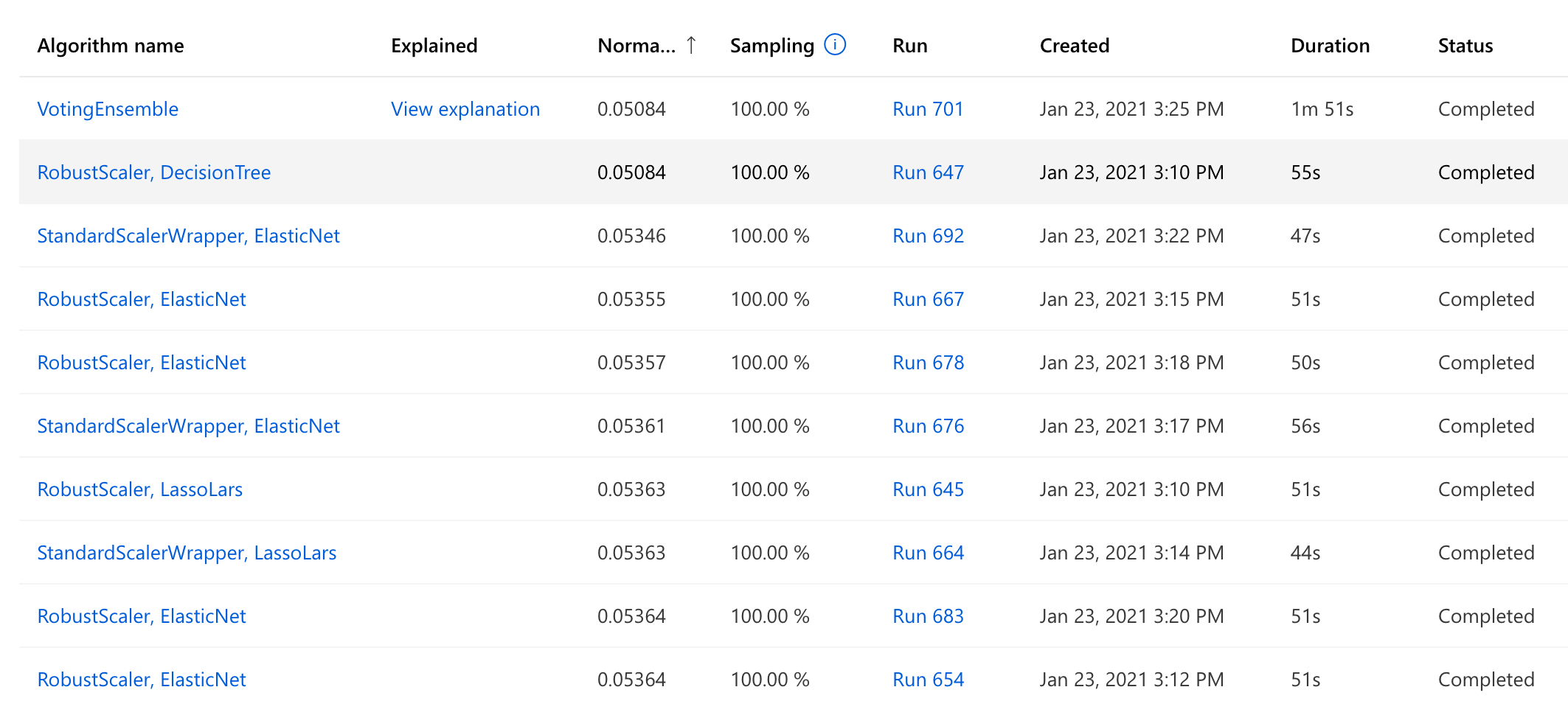
If you want to follow along with the code examples and you haven’t went through my previous article yet, then feel free to download the model here.
Analyzing the Forecasting Model
To be able to run the code and load the Azure AutoML models, make sure you have a conda environment set up with the Azure ML SDK. You can install it locally as per the official instructions, and don’t forget to include the automl optional package. Alternatively, you can just create a new Azure Notebook and be done with it - it’ll have most of the packages you need, and you can pip install the others (joblib, workalendar).
Let’s load the model and see what it looks like.
import joblib
model = joblib.load('model.pkl')
model
Which looks like this:
ForecastingPipelineWrapper(
pipeline=Pipeline(memory=None,
steps=[('timeseriestransformer',
TimeSeriesTransformer(featurization_config=None,
pipeline_type=<TimeSeriesPipelineType.FULL: 1>)),
('MinMaxScaler',
MinMaxScaler(copy=True,
feature_range=(0, 1))),
('DecisionTreeRegressor',
DecisionTreeRegressor(ccp_alpha=0.0,
criterion='friedman_mse',
max_depth=None,
max_features=None,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
min_samples_leaf=0.006781961770526707,
min_samples_split=0.015297321160913582,
min_weight_fraction_leaf=0.0,
presort='deprecated',
random_state=None,
splitter='best'))],
verbose=False),
stddev=None)
As you can see, the model is using the standard Pipeline pattern, with three steps:
- an Azure ML-specific time series transformer, most likely used to extract all possible features from the initial features
- a standard MinMaxScaler, used for scaling all features to the same range
- another standard DecisionTreeRegressor, used for, well, you know, 🧙♂️
This is basically the same structure of each and every forecasting model generated by AutoML: a time series transformer, a scaler, and a regressor. The only exceptions are models trained with Auto-ARIMA and Prophet (which don’t require as much preprocessing), and ensembles (which couple a single time series transformer with entire the ensemble model).
One thing to note is that AutoML isn’t using the standard scikit Pipeline directly, but it instead wraps it in a specialized ForecastingPipelineWrapper. This wrapper pipeline adds quite a few extra methods to its API, including the most useful one for forecasts, forecast.
The forecast method is the magic that enables this model to forecast several days in a series even though it has a forecast horizon of one day. It applies the forecasting model recursively for each and every date in the series, starting at the forecast origin and then successively forecasting each day up until the last one.
As you might imagine, using a model’s imperfect forecasts to forecast other forecasts means that any errors in the model get amplified, and amplified, and then amplified some more. Of course, you’ve probably forecasted that yourself.

Looking at the pipeline’s steps, we see it’s possible to just use the scaler and the regressor in our own standard scikit pipeline. They’re standard scikit modules after all. The only thing we need to do is figure out how to duplicate the TimeSeriesTransformer’s functionality to extract whatever needs to be extracted from our initial features (i.e. the Date column).
By using a standard scikit pipeline instead of the AutoML-specific one we’ll miss out on being able to forecast multiple dates at a time, but we’ll gain significantly lower training times and increased flexibility. Not such a bad trade-off if you ask me.
Now, let’s see what this TimeSeriesTransformer is made of.
Duplicating the Time Series Transformer
The exact features extracted by the TimeSeriesTransformer are controlled by passing certain ForecastingParameters to the AutoML run. Last time we did this, they were set like this:
forecasting_parameters = ForecastingParameters(
time_column_name='Date',
freq='1D',
forecast_horizon=1,
feature_lags='auto',
target_lags=[7],
use_stl=None,
country_or_region_for_holidays='US',
)
Looking at the parameters, we can expect the transformer to generate at least all sorts of features based on date, lagged 7-day values, and holidays for the United States. Let’s run the transformer on a simple dataset and see if that’s the case, trust but verify and all that.
import pandas as pd
from datetime import datetime
# Isolate the transformer step
transformer = model.named_steps['timeseriestransformer']
# Generate a simple dataset
forecast_df = pd.DataFrame({
'Date': pd.date_range(datetime(2021,1,22), datetime(2021,1,30))
})
# See what happens
transformed_df = transformer.transform(forecast_df)
transformed_df
Looking at the generated features, we see that indeed there are several features based on dates like _automl_year, _automl_quarter, _automl_month, _automl_day, _automl_week, features for the seven-day lagged values _automl_target_col_lag7D, and also a plethora of U.S. holiday features – try running list(transformed_df.columns) to see all of them.
In order to duplicate this model, we need to figure out how to generate these features ourselves.
For starters, extracting features such as year, month, day, etc. from dates is pretty straightforward with pandas. We just need to make sure our dataframe has a DatetimeIndex set and then we can just access attributes such as year, month, day and more off the dataframe’s index.
import pandas_datareader as reader
def load_eth_df():
df = reader.get_data_yahoo(['ETH-USD'], start=datetime(2015,7,30))
# Drop duplicate rows
df = df[~df.index.duplicated(keep='first')]
# Get rid of the multi index in columns
df.columns = df.columns.get_level_values(0)
df = df[['Close']]
return df
df = load_eth_df()
# Create features from DatetimeIndex attributes
df['year'] = df.index.year
df['quarter'] = df.index.quarter
df['month'] = df.index.month
df['day'] = df.index.day
df['dayofyear'] = df.index.dayofyear
df['days_in_month'] = df.index.days_in_month
df['is_month_start'] = df.index.is_month_start
df['is_month_end'] = df.index.is_month_end
df['is_year_start'] = df.index.is_year_start
df['is_year_end'] = df.index.is_year_end
df['hour'] = df.index.hour
df['weekday'] = df.index.weekday
Generating holiday features is a bit more complicated, but not by much. Using the excellent workalendar package, we can easily determine whether or not a specific day is a holiday.
Even more, we can do this for several calendars, not just for the United States – see below how to generate features for the Western, Orthodox, and ChineseNewYear calendars.
from workalendar.core import WesternCalendar, OrthodoxCalendar, ChineseNewYearCalendar
calendars = {
'western': WesternCalendar(),
'orthodox': OrthodoxCalendar(),
'chinese_new_year': ChineseNewYearCalendar()
}
for key in calendars:
calendar = calendars[key]
print(key, calendar)
df[f'is_{key}_holiday'] = df.index.to_series().apply(lambda x: calendar.is_holiday(x))
df[f'is_{key}_working_day'] = df.index.to_series().apply(lambda x: calendar.is_working_day(x))
Last but not least, the lags can be generated using pandas shift method. This way our model will learn to use last week’s prices as a features, and include them when making predictions.
df['close_lag_7d'] = df['Close'].shift(7)
There’s just one thing left to decide before moving to the next step: how do we use all that feature generating code we’ve just written? 🤨
One way would be to just put all that code in a data processing function somewhere, and call it just before we train our model. But then we’ll need to make sure to call it just before making any predictions, too. Neglecting to do this can affect your model in some very subtle and at times, not subtle at all ways.
This difference in performance between training and serving is called training-serving skew, and is described in Google’s Rules of Machine Learning as follows:
Training-serving skew is a difference between performance during training and performance during serving. This skew can be caused by:
- A discrepancy between how you handle data in the training and serving pipelines.
- A change in the data between when you train and when you serve.
- A feedback loop between your model and your algorithm.
We have observed production machine learning systems at Google with training-serving skew that negatively impacts performance. The best solution is to explicitly monitor it so that system and data changes don’t introduce skew unnoticed.
As per Rule #32, we need to make sure our pre-processing code is reused between the training and the serving pipelines. The easiest way to do this is to actually make it part of the model pipeline, this will ensure that the code gets automatically invoked both when training & running our model.
Luckily, scikit-learn makes adding custom steps to pipelines quite straightforward using Transformers. Below you’ll find a custom Transformer containing all the preprocessing code written so far, plus some extra glue to hold everything together.
from datetime import timedelta
import pandas as pd
from sklearn.base import TransformerMixin
from workalendar.core import WesternCalendar, OrthodoxCalendar, ChineseNewYearCalendar
class TimeSeriesFeaturizer(TransformerMixin):
def __init__(self, lags=None, *featurizers):
self.featurizers = featurizers
self.lags = lags
def fit(self, X, y=None):
self.y = y
return self
def transform(self, X):
df = {}
if isinstance(X, pd.DataFrame):
df = X.copy(deep=True)
elif isinstance(X, pd.Timestamp):
df = pd.DataFrame(index = pd.date_range(X, X))
else:
raise ValueError("TimeSeriesFeaturizer can only process DataFrames or Timestamps")
diff = df[self.y.index[-1] + timedelta(days=1):df.index[-1]]
y_with_blanks = self.y.append(pd.Series(index=diff.index))
df['year'] = df.index.year
df['quarter'] = df.index.quarter
df['month'] = df.index.month
df['day'] = df.index.day
df['dayofyear'] = df.index.dayofyear
df['days_in_month'] = df.index.days_in_month
df['is_month_start'] = df.index.is_month_start
df['is_month_end'] = df.index.is_month_end
df['is_year_start'] = df.index.is_year_start
df['is_year_end'] = df.index.is_year_end
df['hour'] = df.index.hour
df['weekday'] = df.index.weekday
calendars = {
'western': WesternCalendar(),
'orthodox': OrthodoxCalendar(),
'chinese_new_year': ChineseNewYearCalendar()
}
for key in calendars:
calendar = calendars[key]
df[f'is_{key}_holiday'] = df.index.to_series().apply(lambda x: calendar.is_holiday(x))
df[f'is_{key}_working_day'] = df.index.to_series().apply(lambda x: calendar.is_working_day(x))
if self.lags != None:
for lag in self.lags:
df[f'close_lag_{lag}d'] = y_with_blanks.shift(lag).fillna(method='bfill')
return df
Including our custom Transformer in a pipeline is quite straightforward too, as you can see below:
from sklearn.pipeline import make_pipeline
forecasting_model = make_pipeline(
TimeSeriesFeaturizer(lags=[1,7])
)
The Scaler and Regressor
The scaler and regressor are much easier to duplicate – since they’re open source components there’s no need to write any custom code. We’ll just copy their configurations from our original model and add them to our pipeline.
from sklearn.preprocessing import MinMaxScaler
from sklearn.tree import DecisionTreeRegressor
from sklearn.pipeline import make_pipeline
forecasting_model = make_pipeline(
TimeSeriesFeaturizer(lags=[1,7]),
MinMaxScaler(copy=True, feature_range=(0, 1)),
DecisionTreeRegressor(ccp_alpha=0.0, criterion='friedman_mse', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=0.006781961770526707,
min_samples_split=0.015297321160913582,
min_weight_fraction_leaf=0.0, presort='deprecated',
random_state=None, splitter='best')
)
Note that there’s nothing stopping us now from experimenting with various other forecasting pipelines, adding other preprocessing steps, changing (or removing) the scaler, and trying out different regression algorithms. Before we do any of that though, we’re gonna have to build a cross-validation framework to be able to evaluate just how well those pipelines work, and that’s a story for another time.
Testing the End Result
Fitting the model is now as easy as calling fit over our simplified dataframe. The training speed is much improved now, on my laptop for example it runs in about 0.1 seconds.
# Make sure we're using the latest version of the data
df = load_eth_df()
# Et voila!
forecasting_model.fit(df.drop(columns=['Close']), df['Close'])
Our model only supports forecasting the next day in the series, so we’ll find that automatically based on the last day in our training dataset. As before, invoking the model is as easy as calling predict.
# Calculate the next day in the series
target_date = df.index[-1] + timedelta(days=1)
# And find out what price to expect
print(forecasting_model.predict(target_date))
tl;dr;

You’ve seen just how easy it is to create a model based on an Azure AutoML-trained baseline. You’ve learned how to adapt AutoML-specific data preprocessing code and replace it with custom scikit-learn transformers. You’ve also learned how to shamelessly copy other code, all in the name of science. You’ve created a model that works2, and that can be scheduled using Azure ML pipelines to run regularly. In the end, I hope you’ve found this article useful.
If you’ve enjoyed reading this enough to want to read more in-depth articles on Azure ML, subscribe to my newsletter below. I’ll let you know as soon as I write the next one.
Also, if you have other ideas on how to use AutoML then I’d love it if you joined the Twitter conversation.
Wondering how people use #AutoML in their day to day lives. Do you just run it once, or all the time?
— Vlad Iliescu (@vladiliescu) March 24, 2021
Me, I've always found AutoML useful for training an initial baseline model. You know, when you've just managed to get a dataset that's just clean enough to be useful. 1/