
About Orca-2
The fine folk at Microsoft Research have recently published Orca 2, a new small large language model and apparently, it’s quite good!
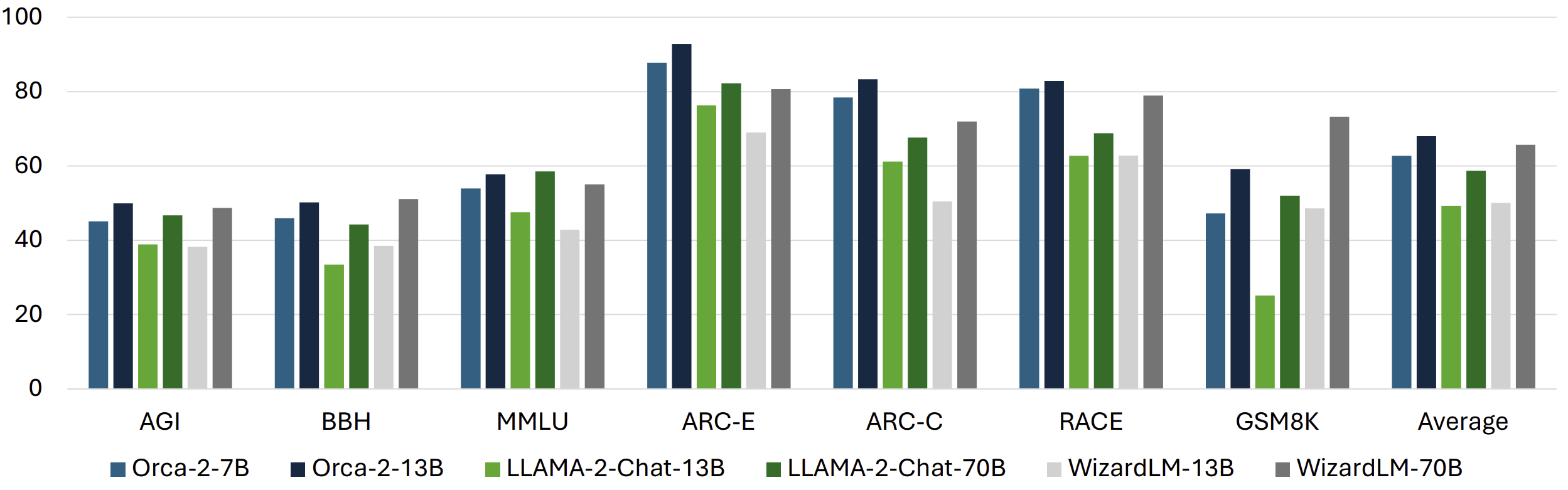
Just look at the test results below – on average, both the 7B and the 13B variants are significantly better than Llama-2-Chat-70B, with Orca-2-13B superseding even WizardLM-70B. Pretty cool!
I also love the idea behind it: prompting a big large language model (in our case GPT-4) to answer some rather convoluted logic questions while aided by some very specific system prompts, and then fine-tune a smaller model (Llama-2-7B and 13B respectively) on just the question and answer pairs, leaving out the detailed system prompts.
They call this approach “Prompt Erasure” and it’s critical in making the smaller models learn to strategize instead of blindly copying the answers of more capable models.
From the paper (which you should totally read):
This Prompt Erasure technique makes Orca 2 a Cautious Reasoner because it learns not only how to execute specific reasoning steps, but to strategize at a higher level how to approach a particular task. Rather than naively imitating powerful LLMs, we treat them as a reservoir of behaviors from which we carefully select those best suited for the task at hand.
To get an idea of how specific the GPT-4 system propts were, here’s an example:
You will be given a task. Use the following steps to solve it.
- Identify the main theme or topic of the story.
- Look for any cause and effect relationships between the sentences.
- Find the sentence that could be the start of the story. Go through each of the answer choices and analyze to figure it out.
- Rearrange the sentences in the correct order based on the information gathered in the previous steps.
- Final answer: Write down the correct order of the sentences using their numbers, such as ‘23415’.
I mean, “think step by step” is child’s play compared to this, they basically teach GPT-4 the algorithm for a very specific type of question.
But that’s ok because remember, this detailed system prompt isn’t included in the fine-tuning data. The only system prompt they’ve used while fine-tuning was this generic one: “You are Orca, an AI language model created by Microsoft. You are a cautious assistant. You carefully follow instructions. You are helpful and harmless and you follow ethical guidelines and promote positive behavior.”
Here’s the training process by the way:
- Start with a collection of diverse tasks
- Group the tasks by the strategy needed to solve them (e.g. direct-answer, step-by-step, explain-then-answer, etc.)
- Write task-specific system instructions corresponding to the chosen strategy in order to obtain teacher (GPT-4) responses for each task. Cheating is ok at this step, multiple calls are ok, very detailed system prompts are ok, etc.
- Prompt Erasing: At training time, replace the student’s system instruction with a generic one vacated of details of how to approach the task.
- Profit 🤑
Not so fast with that last step.
Unfortunately, the license forbids commercial, revenue-generating usage.
So this means we won’t be able to use it in production, but we will be able to use it locally, to experiment and/or maybe run a small MoE using langhain 🤩. It is designed to excel particularly in reasoning after all. And maybe who knows, sometime in the near future, someone might build a free-to-use-for-commercial-stuff Open Orca 2 dataset based on this research. Who knows, indeed.
Until then, let’s see how to run it locally.
Running it locally
Now, the steps to run Orca 2 on Apple Silicon are very similar to those for running Llama 2 on Apple Silicon. Orca 2 is, after all, a Llama 2 fine-tune.
So, the same MacBook Pro M2 hardware, but a newer version of llama.cpp. It also uses a different prompting format (ChatML!), and I wanted to show how to integrate that with llama.cpp.
I’m using Orca-2-13b.
Here’s what you should do:
- Clone or update llama.cpp local repo to at least this commit
- Build
llama.cppwithmake - Either download one of TheBloke’s GGUF model files ( orca-2-13b.Q5_K_M.gguf is cool if you have the RAM), and skip steps 4-8 or you know, go through the journey of learning that are steps 4-8.
- Download the entire
https://huggingface.co/microsoft/Orca-2-13brepo underllama.cpp/models/Orca-2-13bwithgit clone https://huggingface.co/microsoft/Orca-2-13b. You’ll need git lfs installed. Brew some coffee or something, this will take a while – we’re talking about ~50GB worth of weights. - Make sure you’ve also downloaded the meta files: “tokenizer.model”, “added_tokens.json”, “config.json”, “generation_config.json”, “special_tokens_map.json”, and “tokenizer_config.json”
- In the
llama.cppfolder, using conda,
conda create -n llama-cpp python=3.10 -y
conda activate llama-cpp
pip install -r requirements.txt
- Then,
python convert.py models/Orca-2-13bto getggml-model-f32.gguf. Which weighs about 48GB, just so you know 😉. - Time to quantize!
./quantize ./models/Orca-2-13b/ggml-model-f32.gguf ./models/Orca-2-13b/ggml-model-q5_1.gguf q5_1. See here for some (slightly outdated) metrics and options, basically the higher the Q value, the better the model is (and the more RAM it takes). - Phew, we can finally start using the thing! Keep in mind that Orca-2 uses OpenAI’s ChatML format for prompts, we’ll need to adjust the command to accomodate this. Note that I’m using interactive prompting with colors and all, and not limiting the response in any way (
--n-predict -1).
# interactive prompting, with 4096 tokens context size
./main -m ./models/Orca-2-13b/ggml-model-q5_1.gguf \
--ctx-size 4096 --n-predict -1 \
--interactive --interactive-first --color \
--prompt "<|im_start|>system\nYou are a helpful assistant called Chucky Chuckerson." \
--in-prefix "<|im_end|>\n<|im_start|>user\n" \
--in-suffix "<|im_end|>\n<|im_start|>assistant\n"
That’s it, you’ve done it!
You can go ahead and take a look at this reference to get a better idea of what options you have available and how they work.
There’s also the llama.cpp webserver, you can just start this with /server -m models/Orca-2-13b/ggml-model-q5_1.gguf -c 4096 (not sure how to use ChatML with the server 😳).
If you’ve enjoyed this article, you might want to join my low-volume Substack below, just sayin’ 😉.