
Machine learning pipelines are a way to describe your machine learning process as a series of steps such as data extraction and preprocessing, but also training, deploying, and running models.
In this article, I’ll show you how you can use Azure ML Pipelines to deploy an already trained model such as this one, and use it to generate batch predictions multiple times a day. But before we do that, let’s understand why pipelines are so important in machine learning.
Online Versus Offline Learning
First, let’s take a few steps back and think about the best way to run a machine learning model in production. We have basically two options here - either online or offline inference, each with its own advantages & disadvantages.
In online inference you generally have your model up and running continuously on a server, usually exposed as a REST API, generating predictions on demand whenever you need them. In contrast, in offline inference you only run the model from time to time, generating all possible predictions in a batch, removing the need to have your model up all the time.
Choosing one over the other is always a fun architectural decision, and Google’s Machine Learning Crash Course has some pretty good tips on their respective advantages and disadvantages, some of which are quoted below:
Here are the pros and cons of offline inference:
- Pro: Don’t need to worry much about cost of inference.
- Pro: Can likely use batch quota or some giant MapReduce.
- Pro: Can do post-verification of predictions before pushing.
- Con: Can only predict things we know about — bad for long tail.
- Con: Update latency is likely measured in hours or days.
Here are the pros and cons of online inference:
- Pro: Can make a prediction on any new item as it comes in — great for long tail.
- Con: Compute intensive, latency sensitive—may limit model complexity.
- Con: Monitoring needs are more intensive.
Now, a lot of the Azure ML guidance I’ve seen focuses on online inference, which is great when you need just-in-time predictions, and not so great when you need to control costs or return predictions with the lowest latency possible. After all, running a model on a server all the time can be quite expensive, while running it every now and then is definitely cheaper. Batched predictions can be cached and returned almost instantly, too.
In order to balance things out, I’m going to explore the alternative and run a model every now and then to generate batched predictions, which can then be consumed easily by another app/system.
Clean Code with Machine Learning Pipelines
Thinking about the model we’ve trained to predict house prices, we can easily imagine a scenario in which it only needs to run at certain times on a batch of new houses, generate price predictions, and store said predictions for easy access.
The good news is that all of this can be done in a single script containing everything and the kitchen sink, however this approach will not scale particularly well. This is because whenever you’ll need to add more functionality to the script (i.e. by retrieving more features from external APIs), it will grow and grow, acquiring more and more responsibilities, until it becomes a something akin to a big ball of mud.
And who likes mud anyway? Certainly not people like Robert Martin, who introduced a series of design patterns in his Design Principles and Design Patterns paper from 20 years ago, patterns that have since been synthesized by Michael Feathers as the SOLID acronym:
In object-oriented computer programming, SOLID is a mnemonic acronym for five design principles intended to make software designs more understandable, flexible, and maintainable.
(…)
Single-responsibility principle A class should only have a single responsibility, that is, only changes to one part of the software’s specification should be able to affect the specification of the class.
Open–closed principle ”Software entities… should be open for extension, but closed for modification.”
Liskov substitution principle ”Objects in a program should be replaceable with instances of their subtypes without altering the correctness of that program.”
Interface segregation principle ”Many client-specific interfaces are better than one general-purpose interface.”
Dependency inversion principle One should “depend upon abstractions, [not] concretions.”
I’ve found these principles to be worth applying over and over again throughout my professional career, with the Single Responsibility Principle being one of my favorites.
Once we apply SRP to our offline inference scenario, it will lead us to a simple solution - split our big, muddy script into several smaller, focused scripts or steps, each with its own responsibility and purpose. This will make it clearer which script does what and it will also help with composability, allowing us to select and assemble those steps in whichever combination suits our needs. In the end, whenever we’ll need to make changes to our process, we’ll be able to avoid any tight coupling by simply making small changes to our existing steps, or by adding new, focused scripts (incidentally, this means we’ll apply the Open-Closed Principle, too 🤓).
Thus, we can rethink our process as the following series of steps:
- Fetch new data
- Generate predictions for fetched data
- Persist generated predictions
Azure ML Pipelines to the Rescue
Of course, we need some sort of orchestration/coordination for all the steps we’re going to created, otherwise everything gets more complicated instead of simpler.
Incidentally, this is exactly the thing Azure ML Pipelines were created for:
An Azure Machine Learning pipeline is an independently executable workflow of a complete machine learning task. Subtasks are encapsulated as a series of steps within the pipeline. An Azure Machine Learning pipeline can be as simple as one that calls a Python script, so may do just about anything.
The easiest way to understand these pipelines is to actually try them out, and I’ll show you how to do just that.
Keep in mind that you can create pipelines either visually using the Azure Machine Learning designer or directly from Python code, using the Azure Machine Learning SDK. I’m going to show you how to use the latter option, as it provides significantly more flexibility.
Creating Pipelines with the Azure ML SDK
In order to avoid having to install any packages on my local computer, I’ll be using a Jupyter notebook running on an Azure Machine Learning compute instance. They’re easy to use, rather cheap, and come pre-installed with a lot of the packages you’d use anyway. You can provision one by going to Azure Machine Learning studio, and adding a new Compute instance in the Compute menu.
Keep in mind that this compute instance will only be used for testing and deploying the pipeline, with the pipeline actually running on a beefier machine. By beefier machine I mean a compute cluster, such as our compute-optimized instance created when running automl. Personally, I went with a Standard_DS1_v2 machine for the notebook, since that was one of the cheapest options. I named it Scotty. 🚀
All you need to do now is create a notebook from, well, the Notebooks menu. Once created you’ll be able to assign it to your own version of Scotty to run on, and then you’re good to go. Note that you can easily switch the active editor with something more familiar like Jupyter or Jupyter Lab , from the Editors menu.
If you want to follow along, feel free to use the notebook in my GitHub repo.
Now we can go ahead and write some code. 👨🏻💻
Setting up the Azure ML SDK Boilerplate
If you haven’t already, take a look at my previous guide and see how you can train your own model, as the rest of this article pretty much assumes you have done so.
We’ll start off by writing some boilerplate code, setting up our workspace, experiment, and run, all in order to get access to our automatically trained model.
import azureml.core
from azureml.core import Workspace, Experiment
from azureml.train.automl.run import AutoMLRun
from azureml.widgets import RunDetails
from azureml.core.compute import ComputeTarget
from azureml.core.runconfig import RunConfiguration, DEFAULT_CPU_IMAGE
from azureml.core.conda_dependencies import CondaDependencies
from azureml.data.data_reference import DataReference
from azureml.core import Dataset
from azureml.pipeline.core import PipelineParameter
from azureml.pipeline.core import Pipeline, PipelineRun
from azureml.pipeline.steps import PythonScriptStep
from azureml.pipeline.core import PipelineData
from azureml.pipeline.core.schedule import ScheduleRecurrence, Schedule
print('AML SDK version:', azureml.core.VERSION)
# Load the workspace from a configuration file
ws = Workspace.from_config()
# Get a reference to our auto ml experiment
exp = Experiment(ws, 'HousingModel')
We check the SDK version because Microsoft usually pushes out updated versions every two weeks or so, and it makes sense to know what version you’re actually running. In my case, it’s 1.19.0.
Then we can get a reference of our workspace, which we’ll use to get yet another reference, this time to our automated ml experiment. Note that if you’re running this in a local notebook, you should make sure to have a corresponding config.json file as per the official instructions.
We can now go ahead and retrieve our automated ml run with its automatically trained model. We’ll also convert the raw Run class into something richer, in order to get access to model-retrieving APIs.
# Get a list of all previous runs in the experiment
runs = list(exp.get_runs())
# Get the latest automl run. Alternatively, runs[-1] gets the first run
raw_run = runs[0]
# Convert the basic `Run` into the richer `AutoMLRun`, to get some extra APIs
automl_run = AutoMLRun(exp, raw_run.id)
Here comes the fun part. Our automl run actually contains multiple child runs, with each child run representing a scaler & algorithm combo. We can retrieve the best run and the best model of that run using the get_output() method call.
We’ll then register the best model in the versioned Models repository, so we can access it anywhere, including in the pipeline we’re about to create.
# Get the best output of our automl run..
best_run, best_model = automl_run.get_output()
# ..and register it in our Models repository
automl_run.register_model(model_name='HousePrices')
When I first ran this code on my newly-created compute instance, I got a lot of version-mismatch warnings, similar to the ones below. This was because my automated ml experiments had been run weeks before, when SDK version 1.17.0 was the latest and greatest. However, my compute instance had just been created, and it came pre-installed with the latest version available, namely 1.19.0, hence the version mismatch.
You can avoid such mismatches by either pinning the SDK version number used by the notebook to an older version with a conda file, or by re-running the automated ml experiment.
WARNING:root:Received unrecognized parameter enable_pushmode_remote
WARNING:root:Received unrecognized parameter enable_pushmode_remote
WARNING:root:Received unrecognized parameter enable_pushmode_remote
WARNING:root:The version of the SDK does not match the version the model was
trained on.
WARNING:root:The consistency in the result may not be guaranteed.
WARNING:root:Package:azureml-automl-core, training version:1.17.0,
current version:1.19.0
Package:azureml-automl-runtime, training version:1.17.0, current version:1.19.0
Package:azureml-core, training version:1.17.0, current version:1.19.0
Package:azureml-dataprep, training version:2.4.0, current version:2.6.1
Package:azureml-dataprep-native, training version:24.0.0, current version:26.0.0
Package:azureml-dataprep-rslex, training version:1.2.0, current version:1.4.0
Package:azureml-dataset-runtime, training version:1.17.0, current version:1.19.0
Package:azureml-defaults, training version:1.17.0, current version:1.19.0
Package:azureml-interpret, training version:1.17.0, current version:1.19.0
Package:azureml-pipeline-core, training version:1.17.0, current version:1.19.0
Package:azureml-telemetry, training version:1.17.0, current version:1.19.0
Package:azureml-train-automl-client, training version:1.17.0,
current version:1.19.0
Package:azureml-train-automl-runtime, training version:1.17.0,
current version:1.19.0
WARNING:root:Please ensure the version of your local conda dependencies match the
version on which your model was trained in order to properly retrieve your model.
We’re now going to create a pipeline comprised of all our three steps: fetching new data, generating predictions for fetched data, and persisting those predictions. It should look something like this:
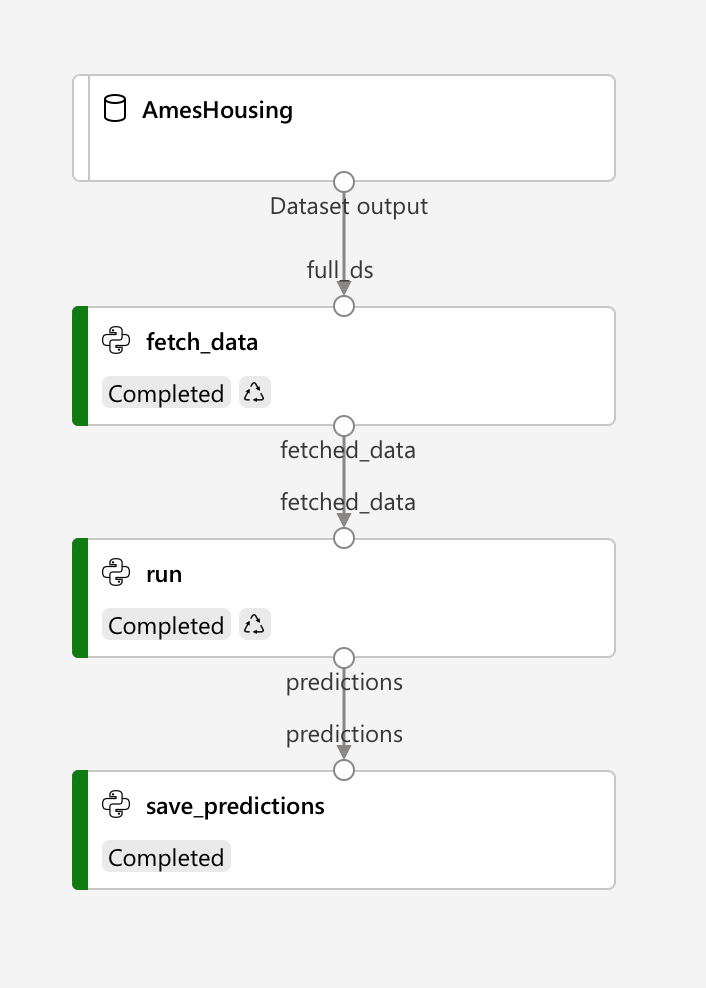
You’ll notice that each step has its own inputs and outputs, with data flowing from one step to the next, and it all starts with our AmesHousing dataset. This is because we’ll simulate the actual data fetching by taking a small sample out of the original dataset, and passing it to our trained model for predictions.
Basically, the fetch_data step will get a reference to our training dataset, retrieve a random sample and pass it to the run step. The run step in turn will load our trained model from the model repository and use it to generate predictions for the sample data, which it will then pass to the save_predictions step. This final step will receive the generated predictions and persist them to Azure storage. Easy peasy.
Step 1: Fetching New Data
The first step of the pipeline is configured easy enough - we just need to tell it what inputs & outputs to use, and also which compute to run on.
# Use Spock, the compute we created when experimenting with automated ml
compute = ComputeTarget(workspace=ws, name='Spock')
compute.wait_for_completion(show_output=True)
# Get a reference to our AmesHousing dataset..
ds = Dataset.get_by_name(ws, 'AmesHousing')
# ..and convert it to a pipeline input
full_ds = ds.as_named_input('full_ds')
# Define the step's output
fetch_data_param = PipelineData('fetched_data')
# Put it all together
fetch_step = PythonScriptStep(
name='fetch_data',
script_name='fetch.py',
arguments=['--fetched_data', fetch_data_param],
inputs=[full_ds],
outputs=[fetch_data_param],
compute_target=compute,
source_directory='./fetch_data',
allow_reuse=False
)
The fragment above describes where the step will run, what inputs and outputs it will receive, however the actual code being run is specified in an external script file - fetch_data/fetch.py.
# Make sure to create the directory first
!mkdir fetch_data
%%writefile fetch_data/fetch.py
from azureml.core import Run
# Retrieve our input from the current run context
ds = Run.get_context().input_datasets['full_ds']
df = ds.to_pandas_dataframe()
print(df)
# Sample 10 houses and make sure to drop the target column
forecast_df = df.sample(10).drop(columns='SalePrice')
print(forecast_df)
# Parse the `fetched_data` argument, this is the location where we should save
# the output
parser = argparse.ArgumentParser()
parser.add_argument('--fetched_data', dest='fetched_data', required=True)
args = parser.parse_args()
print(args.fetched_data)
# Save the output, the AML pipeline infrastructure will take care
# of passing it to the next steps
forecast_df.to_csv(args.fetched_data, index=False)
Step 2: Generating Predictions for Fetched Data
The second step in our pipeline is just a bit more complex. Apart from using the output of fetch_data as its input, it also specifies a RunConfiguration. You generally want to specify a run configuration whenever you’d like to be able to customize the packages installed on the compute resource, which is exactly what I hoped to achieve. Here, I wanted to be able to use joblib to deserialize the persisted model.
# Define the step's output
predictions_param = PipelineData('predictions')
# Specify a configuration manually
run_config = RunConfiguration()
run_config.environment.docker.enabled = True
# It might be a good idea to pin a specific version of the AML SDK here
conda = CondaDependencies()
conda.add_pip_package('azureml-sdk[automl]')
conda.add_pip_package('joblib')
conda.add_pip_package('xgboost==0.90')
run_config.environment.python.conda_dependencies = conda
# discuss allow reuse for first two steps
run_step = PythonScriptStep(
name='run',
script_name='run.py',
arguments=['--fetched_data', fetch_data_param, '--predictions', predictions_param],
inputs=[fetch_data_param],
outputs=[predictions_param],
compute_target=compute,
runconfig = run_config,
source_directory='./run',
allow_reuse=False
)
Create the corresponding script, too.
!mkdir run
%%writefile run/run.py
from azureml.core import Run, Model, Workspace
import joblib
import pandas as pd
# Parse arguments
parser = argparse.ArgumentParser()
parser.add_argument('--fetched_data', dest='fetched_data', required=True)
parser.add_argument('--predictions', dest='predictions', required=True)
args = parser.parse_args()
print(args.fetched_data)
print(args.predictions)
# Read the input data
df = pd.read_csv(args.fetched_data)
print(df)
# Get the current context's workspace..
ws = Run.get_context().experiment.workspace
print(ws)
# ..in order to be able to retrieve a model from the repository..
model_ws = Model(ws, 'HousePrices')
# ..which we'll then download locally..
pickled_model_name = model_ws.download(exist_ok = True)
# ..and deserialize
model = joblib.load(pickled_model_name)
print(model)
# ..and use to predict the house prices
results = model.predict(df)
print(results)
# The predictions are stored in the `predictions` output path
# so that AML can find them and pass them to other steps
df['PredictedSalePrice'] = results
df.to_csv(args.predictions, index=False)
Step 3: Persisting the Generated Predictions
Our final step is quite a bit simpler as it only needs to retrieve the predictions and store them.
Now, you might think that this is certainly something that the run step could have done, and of course, you would be right. However, persisting predictions is not exactly something that a step named run should be concerned with - it should be only concerned with running the model, anything else being outside its area of responsibility. So we’ll persist the predictions in a separate step.
An added bonus of keeping things separated is that when the storage needs will invariably change you’ll be able to support any scenarios easily, by just replacing this step.
save_step = PythonScriptStep(
name='save_predictions',
script_name='save.py',
arguments=['--predictions', predictions_param],
inputs=[predictions_param],
compute_target=compute,
source_directory='./save_predictions',
allow_reuse=False
)
And save_predictions/save.py.
!mkdir save_predictions
%%writefile save_predictions/save.py
from azureml.core import Run, Model, Workspace
import pandas as pd
import os
# Parse arguments and print the `predictions` input
parser = argparse.ArgumentParser()
parser.add_argument('--predictions', dest='predictions', required=True)
args = parser.parse_args()
print(args.predictions)
# Read the dataset
df = pd.read_csv(args.predictions)
print(df)
# Get a reference to the workspace's default data store, we'll use this
# to save the predictions
ws = Run.get_context().experiment.workspace
ds = ws.get_default_datastore()
# Create a folder and persist the predictions inside
os.mkdir('./out')
df.to_csv('./out/predictions.csv')
# Upload the folder to the workspace's default data store
ds.upload('./out', target_path='latest_predictions')
Running an Azure ML Pipeline
With all pipeline steps defined and configured, all we need to do is assign them to a Pipeline object and use that to submit a run.
Azure ML will create a new experiment, and use it to run the pipeline. You’ll be able to see its progress in Studio, in either the Experiments or the Pipelines sections.
pipeline = Pipeline(workspace=ws, steps=[fetch_step, run_step, save_step])
pipeline.validate()
pipeline.submit('IRunPipelines')
After the pipeline has run, you can check the IRunPipelines experiment and check that everything went well. You can also take a look at your workspace’s associated blob container, and verify that it contains the latest_predictions folder.

Scheduling Pipelines
Now that we’ve successfully ran a pipeline, let’s see how we can schedule it to run several times a day, every day.
The simplest way to do this is using Azure ML’s built-in support for scheduling pipelines - we’ll need to first publish the pipeline, and then set it to run several times a day using a ScheduleRecurrence.
# Publish the pipeline first, so that we can reference it when defining the schedule
published_pipeline = pipeline.publish()
# Run twice a day, every day
recurrence = ScheduleRecurrence(frequency='Day', interval=1, hours=[1, 13], minutes=[30])
recurring_schedule = Schedule.create(ws, name='DailySchedule',
description='Twice a day, at 01:30 and 13:30',
pipeline_id=published_pipeline.id,
experiment_name='IRunScheduledPipelines',
recurrence=recurrence)
Once you’ve run the code above, the new schedule should appear in the pipeline’s schedules list.
schedules = Schedule.list(ws, pipeline_id=published_pipeline.id)
schedules
In case you change your mind about the schedule, deactivating it is also done quite easily.
# Disable/enable all schedules of a pipeline
for schedule in schedules:
schedule.disable()
#schedule.enable()
Scheduling pipelines like this is pretty straightforward, however if you need more flexibility in doing this there are other options too, such as using Azure Functions, Azure Logic apps, even from Azure DevOps release pipelines.
If you’ve enjoyed this article, please do show the Twitter thread some love:
I've written what was supposed to be a short-ish guide on Azure ML Pipelines, but got a bit sidetracked explaining my reasoning and turned into something quite a bit longer. I think it's significantly more valuable this way though. 🧵https://t.co/QoSzI8Qpmq
— Vlad Iliescu (@vladiliescu) January 4, 2021
And if you want to learn more about using Azure Machine Learning in real-life, join my email list below. Reading my other pipeline-focused article detailing 3 ways to pass data between Azure ML pipeline steps will also help. See you soon! 👋